机器学习中如何“正确”的进行模型选择
Table of Contents
本文由作者原创,未经允许禁止转载。联系marcnuth(AT)foxmail.com了解转载事宜。
1 何为“正确”的模型选择
1.1 入门级的模型选择策略
我们都知道,对于一个机器学习模型而言,我们期望它更加准确的在任意数据集上都能给出预测结果,尽可能的降低预测的误差。因此,显而易见的,在选择模型时,我们会选取误差更小的模型。 即,通常的模型选择策略可能是这样:
- 训练模型A和模型B
- 计算模型A和模型B各自的训练误差
- 比较两个误差,选取较小的一个,并认为其为更好的模型
当然,大家都知道机器学习中的某些模型本身就是具有随机性的,所以同一个模型同一份数据得到的训练误差可能不一样。所以,对上述步骤可能会做如下改进:
- 将数据集划为n份(随机或等分,取决于训练者的策略)
- 用n份数据集各自训练模型A和模型B
- 计算模型A和模型B的误差均值(或中值)作为最终误差
- 选取误差更小的模型
但是事实上,即便做了这样的改进,这两个模型选择策略在本质上都是一样的,那就是 “基于误差的大小比较来选择模型” 。
1.2 入门级的模型选择策略可能出现的问题
为什么基于误差的大小比较来选择模型会出现问题呢?考虑以下几点:
- 一个“好”的模型,应该是 泛化能力 好。即该模型的泛化误差更低。 因此,如果我们知道不同模型的泛化误差,直接比较大小肯定是一个简单好用的选择策略。 但是事实是,数据集有限,我们无法计算出泛化误差,我们只能通过一些训练集计算得出训练误差。 虽然我们理想的认为 训练误差近似等于泛化误差 ,但是也只是 近似等于 ,所以比较训练误差的大小并没有多大的意义。
- 测试误差很大程度上依赖于选取的测试集,如果测试不同模型的测试集不同,比较误差是没有意义的。
- 算法模型本身具有随机性,即便是同一个数据集同一个模型,2次得到的结果也可能不一样。所以在这种情况下,比较大小也可能是不正确的。
1.3 有没有“正确/更好”的策略来进行模型选择
答案就是 假设检验 。
假设检验是基于样本的一种统计推断方法。基于假设检验,我们可以推断若模型A在测试集上表现的比B好,则A的泛化能力是否在统计意义上比B更好,以及这样的把握(概率)有多大。 若您对假设检验还不是很了解,可以参考我之前写过的文档 《谈谈假设检验》 。
2 TODO 如何“正确”的选择模型
2.1 TODO 从检验测试误差说起
在探究如何用假设检验选择模型之前,我们先谈谈测试误差和泛化误差。
在前一节中,我们提到测试误差和泛化误差是不尽相同的。假设我们现在有模型A,是否可以利用假设检验来判断他们相等的概率呢?
设想基于用于分类的模型A:
- 测试错误率 = \(\hat{\epsilon}\) = 预测错误的测试样本数 / 总测试样本数
- 泛化错误率 = \(\epsilon\)
- 总测试样本数 = m
2.2 TODO 使用假设检验进行模型选择
2.2.1 TODO t检验
2.2.2 TODO McNemar 检验
2.2.3 TODO Friedman 检验
2.2.4 TODO Nemenyi 检验
3 评价过程中的关键点
3.1 问题描述
从模型角度说,可能有这些场景:
- 针对一个模型,如何评价该模型在改进前后的效果是否提升?
- 针对多个模型,如何评价在这些模型中,好坏的次序是怎么样的?
归结到底,就是一个问题, 如何对比不同模型之间的效果。
从评价函数角度说,可能有这些场景:
- 这对某一个问题,应该采用什么样的评价函数和评价指标? 评价函数和指标和数据集之间的关系应该处理?
- 如何应对训练误差/验证误差 和 测试误差不一致(过拟合)的问题?
3.2 关键点
3.2.1 测试集
关键问题:如何才能获得一个模型的 无偏差 的训练精度(也可以是其他指标)?
- 在训练模型时,不能使用测试集的数据!
- 测试集的标记应当是不能影响模型的!
3.2.2 验证集
将训练集拆分出一部分作为验证集 可能存在的问题:
- 更大的验证集可能更好的帮助我们计算出“无偏差”的评测指标,但是更大的训练集可以帮助模型更好的学习。因此,从训练集中拆分验证集 是一件矛盾的事情。
- 单独一个训练集并不能很好的帮助我们判断模型对评测指标的影响。
3.2.3 学习曲线
关键问题:模型的训练精度和训练样本空间的大小之间是怎样的关系?
通过学习曲线可以画出训练精度和样本空间之间的关系。具体步骤为:
- 选取一个样本空间大小,随机取样作为训练集,训练模型并得到评测结果
- 反复进行#1, 画出学习曲线图
3.2.4 取样
在画学习曲线的问题中,我们通过随机取样来选取训练集。因此评测结果可能会受到“随机性”的影响,并且,我们无法判断这种影响的程度大小。
针对分类算法,一种更合理的办法可能是分层抽样。例如,对于二分类问题,对每种类别都抽取一定的样本,并且保证抽取的正负样本比例与原数据集近似一致。
3.2.5 交叉检验
原理: 将训练集分成K份,在每次迭代中,将K-1份用于训练,剩下一份用于测试验证。即为K-fold交叉检验。
- 现实中,K通常取值10,但是小于10的K值也很常见,因为K值越大所花费的时间越多。
- 在留一检验中, K=样本空间大小
- 在分层交叉检验中,即在划分训练集的时候,采取分层采样的办法来提取每一份训练集。
- 交叉检验通常被用于评价模型的好坏,当然也可以被用来帮助选取更好的模型。
为了避免交叉检验中常出现的陷阱,要关注以下几点:
- 是否数据来源是一致的?
例如,对于某项疾病的样本空间中,有病和无病的样本来自不同的时间或者不同的医院。
- 整个交叉检验过程中,是否用到了用来预测的数据?
训练数据中不应该包含任何的验证/测试数据!
- 是否已经针对模型做了足够多的优化和调整?
如果已经没有任何优化方向,可以考虑是否需要额外更多的数据。
3.2.6 测试误差的置信区间
计算方法: 前提: 对于模型H, 样本空间大小=n,n>=30,分类错误的样本数为r. H的错误率估计值为: error(H) = r/n
则当置信度为P时, 则真实的误分类率应该位于区间: $$ error(H) \pm Z_P \sqrt{\frac{error(H)(1 - error(H))}{n}}$$
当P为95%时, Z = 1.96
我们是如何获取得到这个置信区间的呢?主要是根据以下几点假设:
- 误分类率服从于二项分布,当然,一种更普遍的办法是认为误分类率服从于正态分布
- 当n>=30,且p不是太极端时,使用正态分布比二项分布更好
- 通过假设检验计算
还有一种简单办法即为: 计算多次的平均值, +- 方差作为误差区间
3.2.7 Empirical Critical Bound
经验之谈
- bootstrapping: 从样本空间中随机/uniformly/independently抽取样本组成训练集
- repeating: 重复1000次#1
- 得到评测标准的 两侧2.5% 即为 lower/higher bound
3.2.8 模型之间的对比
针对两个模型,比较
- 针对某种特定的任务,是否模型A比B更好?
- 针对某个训练集, 是否模型A比B更好?
使用成对t检验! 原假设: 两个模型的一样好(准确率/其他评测指标一样) 备择假设: 两个模型中有一个模型更好
典型情况下, 当p < 0.05 拒绝原假设
还可以使用的检验方法为 符号检验(sign test)!
- 如果样本数只有300个,进行10重交叉检验后,测试样本数不足30个
- 数据量较小时,使用留一交叉检验的办法更好
3.2.9 lesion studies
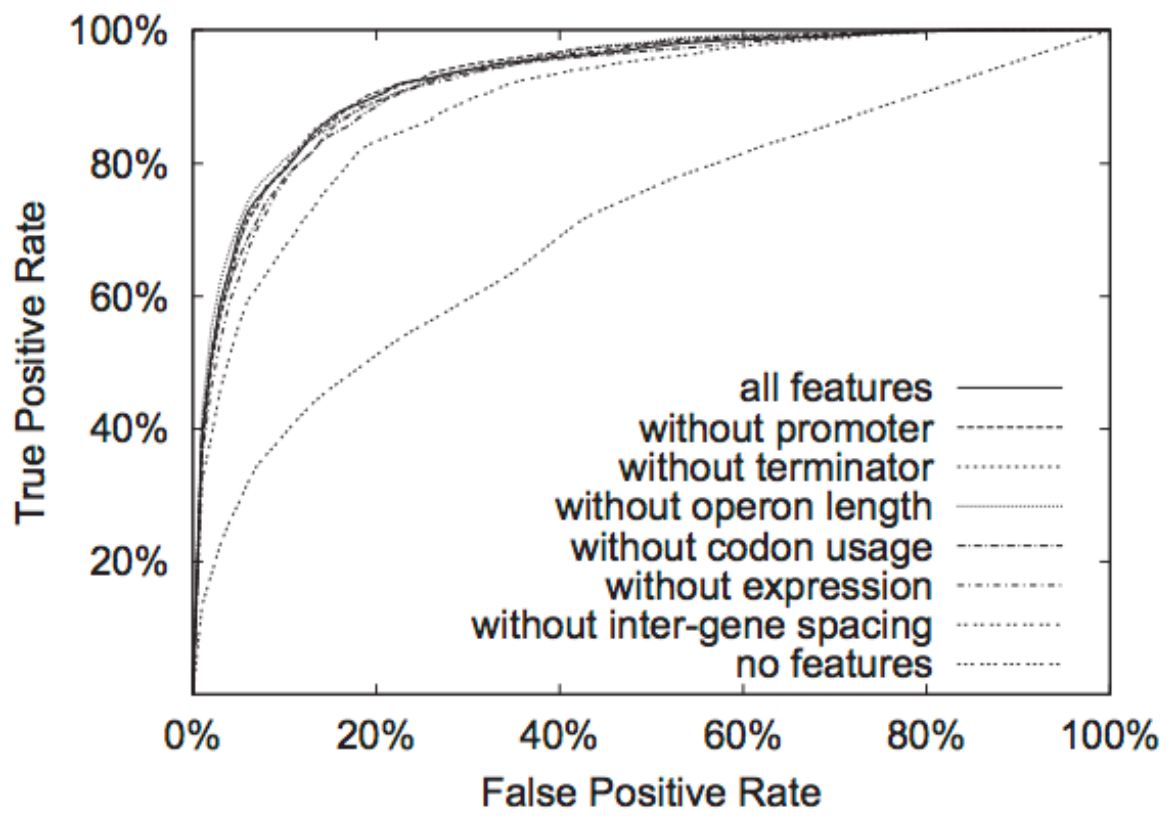
通过移除算法中的某个元素(特征/处理步骤等),我们可以通过ROC曲线来判断模型的表现是否更好。 例如: 通过移除一些特征,画出不同的ROC曲线,从而判断哪些feature是应该被移除的。
{kind=link}
4 其他经验
4.1 Test Harness
Test Harness 是指用于测试所需要的一系列东西。在验证机器学习模型的场景中,包含了所需要使用的数据集以及一些评价指标。 Test Harness 的目的是为了建立起良好的评测“框架”,通过这套框架得到的结果可以帮助你去选择那个模型更好,或者选择在哪个模型上进行优化。 Test Harness 是从测试框架的角度出发,关键想法使使得评价算法所使用的数据和指标都是一致的,但是不涉及具体的评价细节。
4.2 评测指标
机器学习中,针对不同的数据集及问题,应当有不同的评测指标。
4.3 数据集(测试/验证/训练)
数据集的选取很关键,直接关系到模型的结果。
4.4 模型检测手段
- 选取5-10个适合你问题的模型,并且在使用默认参数的情况下通过你的Test Harness测试出一个结果。
- 根据1的结果,你可以给自己的算法设置一个基准,如果你的调优模型比设定的基准表现还糟糕,就没有继续调优的必要了。
- 当然,你也可以从1的模型中,选取一些表现较好的模型进行下一步的调优。